This is not going to be your typical tech conference talk: I will be building an asset tracking solution from scratch, sharing tons of tips along the way, and answering any questions you may have!
More than a presentation or a workshop, I hope this will be a great conversation with all of you interested in IoT development, whatever your level of expertise might be. I also hope this will be the first occurrence of many more live IoT coding sessions in the near future!
We will be going live at 1pm CEST (that’s 11am GMT). If there are topics you’d like to see covered, please feel free to let me know in the comments!
This post will be a short one in my ongoing series about TinyML and IoT (check out my previous post and video demo here).
In a nutshell, you will learn how to run the TensorFlow Lite “Hello World” sample on an MXChip IoT developer kit. You can jump directly to the end of the post for a video tutorial.
You may have not realized, but unless you are looking at real-time object tracking, complex image processing (think CSI crazy image resolution enhancement, which turns out to be more real than you may have initially thought!), there is a lot that can be accomplished with fairly small neural networks, and therefore reasonable amounts of memory and compute power. Does this mean you can run neural networks on tiny microcontrollers? I certainly hope so since this is the whole point of this series!
TensorFlow on microcontrollers?
TensorFlow Lite is an open-source deep learning framework that enables on-device inference on a wide range of equipment, from mobile phones to the kind of microcontrollers that may be found in IoT solutions. It is, as the name suggests, a lightweight version of TensorFlow.
When TensorFlow typically positions itself has a rich framework for creating, training, and running potentially very complex neural networks, TensorFlow Lite only focuses on inference. It aims at providing low latency, and small model/executable size, making it an ideal candidate for constrained devices.
In fact, there is even a version of TensorFlow Lite that is specifically targetted at microcontrollers, with a runtime footprint of just a couple of dozens of kilobytes on e.g. an Arm Cortex M3. Just like a regular TensorFlow runtime would rely on e.g. a GPU to train or evaluate a model faster, TensorFlow Lite for micro-controllers too might leverage hardware acceleration built into the microcontroller (ex. CMSIS-DSP on Arm chips, which provides a bunch of APIs for fast math, matrix operations, etc.).
A simplified workflow for getting TensorFlow Lite to run inference using your own model would be as follows:
First, you need to build and train your model (❶). Note that TensorFlow is one of the many options you have for doing so, and nothing prevents you from using PyTorch, DeepLearning4j, etc. Then, the trained model needs to be converted into the TFlite format (❷) before you can use it (➌) in your embedded application. The first two steps typically happen on a “regular” computer while, of course, the end goal is that the third step is happening right on your embedded chip.
In practice, and as highlighted in the TensorFlow documentation, you will probably need to convert your TFlite model in the form of a C array to help with inclusion in your final binary, and you will, of course, need the TensorFlow Lite library for microcontrollers. Luckily for us, this library is made available in the form of an Arduino library so it should be pretty easy to get it to work with our MXChip AZ3166 devkit!
TensorFlow Lite on MXChip AZ3166?
I will let you watch the video below for a live demo/tutorial of how to actually run TensorFlow Lite on your MXChip devkit, using the Hello World example as a starting point.
Spoiler alert: it pretty much just works out of the box! The only issue you will encounter is described in this Github issue, hence while you will see me disabling the min() and max() macros in my Arduino sketch.
For the past few weeks, I’ve been spending some time digging into what some people call AIoT, Artificial Intelligence of Things. As often in the vast field of the Internet of Things, a lot of the technology that is powering it is not new. For example, the term Machine Learning actually dates back to 1959(!), and surely we didn’t wait for IoT to become a thing to connect devices to the Internet, right?
In the next few blog posts, I want to share part of my journey into AIoT, and in particular I will try to help you understand how you can:
Quickly and efficiently train an AI model that uses sensor data ;
Run an AI model with very limited processing power (think MCU) ;
Remotely operate your TinyML* solution, i.e. evolve from AI to AIoT.
* TinyML: the ability to run a neural network model at an energy cost of below 1 mW.
According to Wikipedia, supervised learning is the machine learning task of learning a function that maps an input to an output based on example input-output pairs.
As an example, you may want to use input data in the form of vibration information (that you can measure using, for example, an accelerometer) to predict when a bearing is starting to wear out.
You will build a model (think: a mathematical function on steroids!) that will be able to look at say 1 second of vibration information (the input) and tell you what the vibration corresponds to (the output – for example: “bearing OK” / “bearing worn out”). For your model to be accurate, you will “teach” it how to best correlate the inputs to the outputs, by providing it with a training dataset. For this example, this would be a few minutes/hours worth of vibration data, together with the associated label (i.e., the expected outcome).
Adding some AI into your IoT project will often follow a similar pattern:
Capture and label sensor data coming from your actual “thing” ;
Design a neural network classifier, including the steps potentially needed to process the signal (ex. filter, extract frequency characteristics, etc.) ;
Train and test a model ;
Export a model to use it in your application.
All those steps might not be anything out of the ordinary for people with a background in data science, but for a vast majority—including yours truly!—this is just too big of a task. Luckily, there are quite a few great tools out there that can help you get from zero to having a pretty good model, even if you have close to zero skills in neural networks!
Enter Edge Impulse. Edge Impulse provides a pretty complete set of tools and libraries that provides a user-friendly (read: no need to be a data scientist) way to:
They have great tutorials based on an STM32 developer kit, but since I didn’t have one at hand when initially looking at their solution, I created a quick tool for capturing accelerometer and gyroscope data from my MXCHIP AZ3166 Developer Kit.
In order to build an accurate model, you will want to acquire tons of data points. As IoT devices are often pretty constrained, you often need to be a bit creative in order to capture this data, as it’s likely your device won’t let you simply store megabytes worth of data on it, so you’ll need to somehow offload some of the data collection.
Edge Impulse exposes a set of APIs to minimize the number of manual steps needed to acquire the data you need to train your model:
The ingestion service is used to send new device data to Edge Impulse ;
The remote management service provides a way to remotely trigger the acquisition of data from a device.
As indicated in the Edge Impulse documentation, “devices can either connect directly to the remote management service over a WebSocket, or can connect through a proxy”. The WebSocket-based remote management protocol is not incredibly complex, but porting it on your IoT device might be overkill when in fact it is likely that you can simply use your computer as a proxy that will, on the one hand, receive sensor data from your IoT device, and on the other hand communicate with the Edge Impulse backend.
So how does it work in practice should you want to capture and label sensor data coming from your MXChip developer kit?
Custom MXChip firmware
You can directly head over to this GitHub repo and download a ready-to-use firmware that you can directly copy to your MXChip devkit. As soon as you have this firmware installed on your MXChip, its only purpose in life will be to dump on its serial interface the raw values acquired from its accelerometer and gyroscope sensors as fast as possible (~150 Hz). If you were to look at the serial output from your MXChip, you’d see tons of traces similar to this:
There would probably be tons of better options to expose the sensor data over serial more elegantly or efficiently (ex. Firmata, binary encoding such as CBOR, etc.), but I settled on something quick 🙂.
Serial bridge to Edge Impulse
To quickly feed sensor data into Edge Impulse, I’ve developed a very simple Node.js app that reads input from the serial port on the one hand and talks to the Edge Impulse remote management API on the other. As soon as you install and start the bridge (and assuming, of course, that you have an MXChip connected to your machine), you’ll be able to remotely trigger the acquisition of sensor data right from the Edge Impulse portal. You will need to create an Edge Impulse account and project.
npm install serial-edgeimpulse-remotemanager -g
The tool should be configured using the following environment variables:
EI_APIKEY: EdgeImpulse API key (ex. ei_e48a5402eb9ebeca5f2806447218a8765196f31ca0df798a6aa393b7165fad5fe’) for your project ;
EI_HMACKEY: EdgeImpulse HMAC key (ex. ‘f9ef9527860b28630245d3ef2020bd2f’) for your project ;
EI_DEVICETYPE: EdgeImpulse Device Type (ex. ‘MXChip’) ;
EI_DEVICEID: EdgeImpulse Device ID (ex. ‘mxchip001’) ;
SERIAL_PORT: Serial port (ex: ‘COM3’, ‘/dev/tty.usbmodem142303’, …).
Once all the environment variables have been set (you may declare them in a .env file), you can run the tool:
serial-edgeimpulse-remotemanager
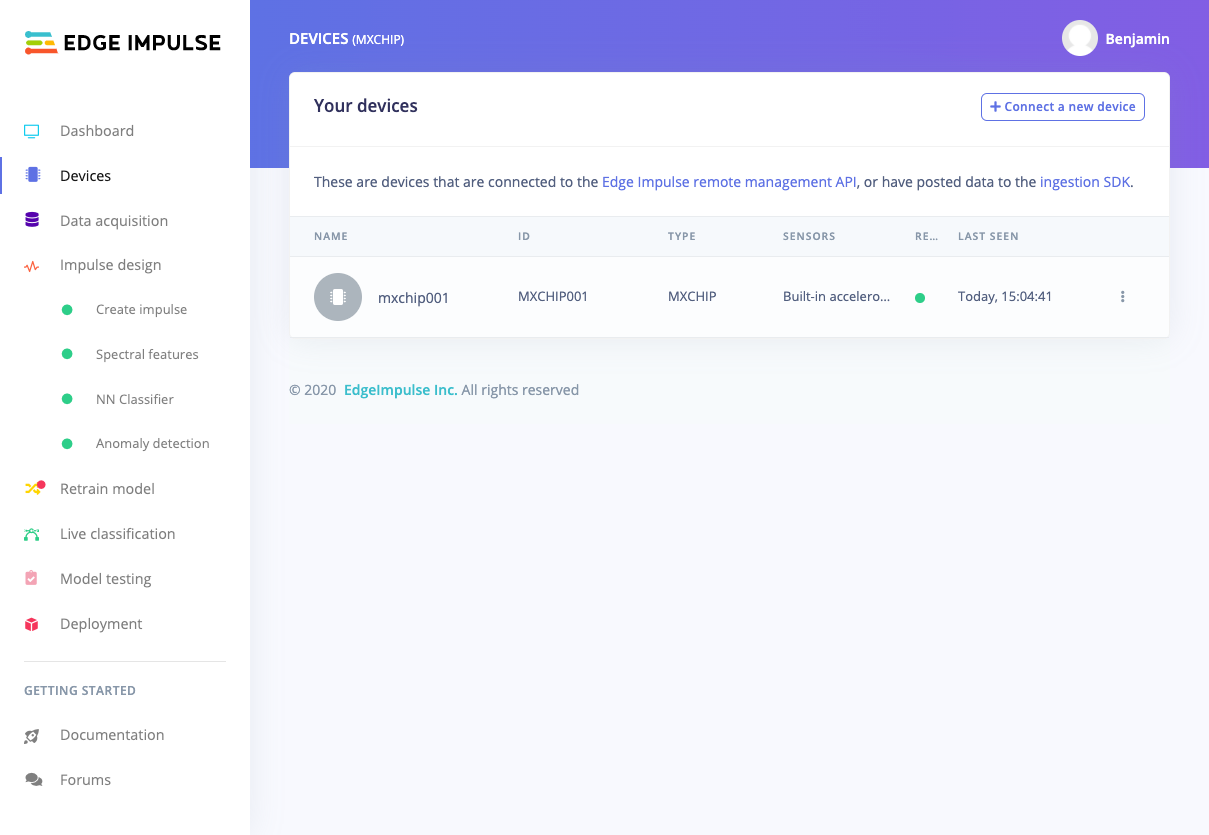
From that point, your MXChip device will be accessible in your Edge Impulse project.
Edge Impulse > Device Explorer
Edge Impulse > Capture
You can now very easily start capturing and labeling data, build & train a model based on this data, and even test the accuracy of your model once you’ve actually trained it.
In fact, let’s check the end-to-end experience with the video tutorial below.
TensorFlow on an MCU?!
Now that we’ve trained a model that turns sensor data into meaningful insights, we’ll see in a future article how to run that very model directly on the MXChip. You didn’t think we were training that model just for fun, did you?
Don’t forget to subscribe to be notified when this follow-up article (as well as future ones!) comes out.